The benefits of being exposed to new subjects are that you tinker with them and start experimenting. Hopefully, this blog leads to some new ideas or at best revisits some established ideas and attempt to show that a less perfect approach might just work. Also keep in mind I’m by no means an expert in advanced automatic code / data flow analysis.
So at my current company, one of our units is doing some pretty cool work with ensuring that security operates at agile speeds, instead of being slow and blocking. One of their areas of focus is the automation of code reviews augmented with human expertise. One of my former colleagues Remco and I got chatting about the subject and he brought me up to speed on the subject. The promising developments in this area (as far as I understood it) concerns the ability to grasp, understand, process the language structure (AST), but also the ability to follow code flows, data types and values and of course lately the practical application of machine learning to these subjects. In a way mimicking how code-reviewers go through code, but using data flow techniques to for example track untrusted (external) input.
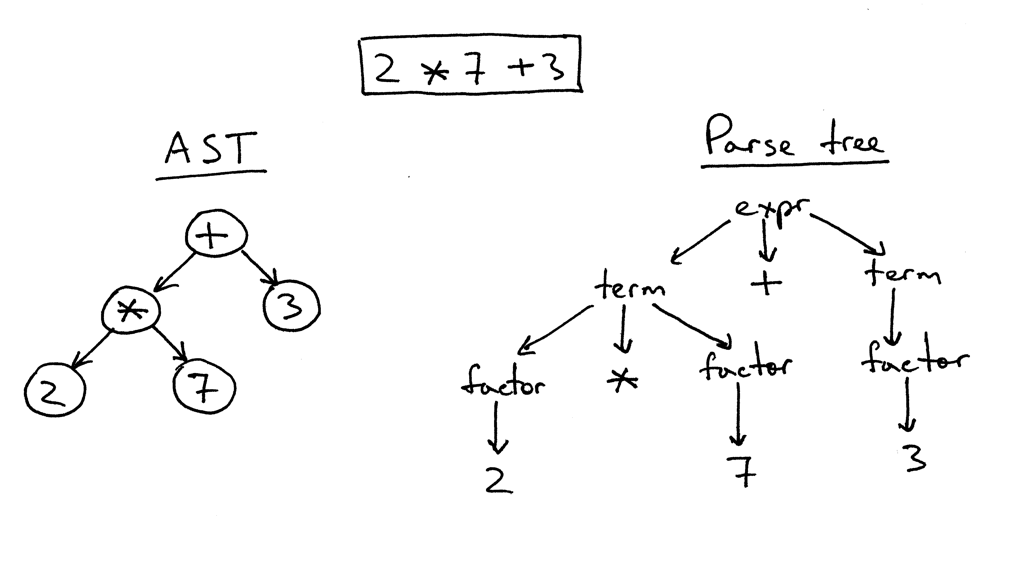
What is it good for? That was my first question. Turns out that if you have the above-described ability, you can more easily and precisely spot potential security flaws in an automated manner. It also enables you to create repeatable queries that enable you to quickly weed out security vulnerabilities and detect them if they or variants somehow creep back into the source.
Because just as with regular ‘user security awareness’, an automated and fool-proof process will beat ‘awareness’ every time. Having security aware developers is not bad, but having automated processes and process-failure detection is even better.
However, the above is pretty complex, so I decided to tinker with a less optimal and perfect solution and see what I could do with it. My main goal was to achieve the following:
Enable a guesstimate on what part of a code base could be considered ‘risky’ security wise. Capture the code reviewers knowledge and improve the guesstimate of ‘risky’ parts of a code base.
The above would result in an improved ability to process codebases according to a more risk-based approach, without continuously needing expensive experts. It would however not be fully precise, generation of false positives. The lack of precision I accept in return for the ability to at least have a guesstimate on where to spend focus and effort.
If you are still interested, keep on reading. Just don’t forget that I’m a big fan of: better to progress a bit than no progress at all.
Perfect is the enemy of good
Continue reading “[Part 1] Experimenting with visualizations and code risk overview”
